OIDC what you did there - secure continuous development for your AWS & Azure landing zone
When it comes to developing Infrastructure as Code (IaC), writing is often the hard part and deployment the easy part. But sometimes, it's the other way around. With a range of tools at our disposal, we assessed the best way to robustly and securely grant access permissions at a pace and scale appropriate to our business.
Twinstream operates with a mixture of on-premise and AWS-based resources, using Entra ID (formerly Azure AD) as our identity provider. We have multiple Azure access groups that each grant access to a range of AWS accounts. As a start-up, managing these permissions was a manual process - requests were approved on a case-by-case basis by a director, with little documentation required. We Kept It Simple (Stupid). And it worked. But as the business began to grow at pace, keeping track of permissions and auditing them meant a more automated solution would be needed.
The trappings of Terraform
Moving it all to Terraform seemed like the obvious route to progress. When permissions are stored in a code repository and deployed through a central CI/CD system, Terraform offers an appealing level of self-service:
- Any engineer can raise a pull request
- Change control is effected through a free PR review process
- You have a definitive source of truth of both systems and users giving and receiving permissions
We split our solution into two Terraform projects: one to create Entra Groups in Azure and the other to create AWS accounts and assign access using AWS IAM Identity Center (formerly AWS SSO). Whilst this wouldn't be a workable solution for a business with thousands of employees and AWS accounts, it was viable for a business our size, even with a healthy growth trajectory.
Setting up the projects
In the AWS project, the Terraform required a list of accounts and AWS IAM Identity Center permission sets as variables so it could loop over them to create the necessary resources (example snippet below):
1resource "aws_organizations_account" "this" {
2 lifecycle {
3 ignore_changes = [
4 role_name, // https://github.com/hashicorp/terraform-provider-aws/issues/8947
5 iam_user_access_to_billing // https://github.com/hashicorp/terraform-provider-aws/issues/12959
6 ]
7 }
8 for_each = var.accounts
9 name = each.key
10 email = each.value.email
11 close_on_deletion = true
12 iam_user_access_to_billing = "ALLOW"
13 role_name = "OrganizationAccountAccessRole"
14 parent_id = try(local.created_ous[each.value.ou].id, null)
15}The Azure project was similar, taking a list of group names and members from variables, and then looping over them to generate the resources needed in the same way:
1resource "azuread_group" "all" {
2 for_each = var.groups
3 display_name = each.key
4 description = each.value.description
5 prevent_duplicate_names = true
6 owners = [
7 local.azure_rw_managed_identity_object_id
8 ]
9 security_enabled = true
10 members = compact([for upn in each.value.members : lookup(local.all_users_map, upn, null)])
11}There was nothing too fancy going on with the code, but how could we run it? Because the IaC needed the keys to the kingdom for both AWS and Azure, the potential blast radius for misuse was wide and, as a result, the requirements were rightfully stringent:
- No long-lived credentials could be used.
- Administrators could not have unfettered access; the principle of least privilege was applied at every access level.
- The Azure component only had control over groups it created
- No new third party companies could have direct or indirect control over our AWS accounts or Entra Groups.
- All code had to be reviewed in the source code repository before it could be Terraform applied.
- Every Terraform application had to be reviewed and approved prior to deployment
Application in the pipeline - when is a plan not a plan?
A standard Terraform CI/CD pipeline often consists of a Terraform plan being run when a pull request is created or a commit is pushed. When the PR is merged to the main branch, a Terraform apply is run automatically. Plans are commonly thought of as being read-only operations: Terraform is only checking the current state of objects, so what’s the worst that could happen? A lot, as it turns out.
Terraform HCL (HashiCorp Config Language) is a friendly way to define inputs to providers such as AWS or Azure. They receive your HCL input (transformed into Go in which they are written) and manage the lifecycle of the resources you have defined using the APIs of the underlying service.
During a plan operation, you are relying on the provider’s code to only query the existing state of the input and are assuming it will not attempt a write operation.
What would happen if there was a bug in the code or a malicious operation was included?
- The code would quite happily execute and perform the operation as instructed
- Terraform wouldn't record the creation of the resource in the state file to alert you that it had happened
The built-in external data resource in Terraform will execute any arbitrary code during any plan, making it uncomfortably easy for malicious users to cause disruption. As an example, in an environment with AWS access setup if you performed a Terraform plan using the below code, an SNS topic would be created:
1terraform {
2 required_providers {
3 aws = {
4 source = "hashicorp/aws"
5 version = "5.35.0"
6 }
7 external = {
8 source = "hashicorp/external"
9 version = "2.3.2"
10 }
11 }
12 required_version = "~> 1.3"
13}
14provider "aws" {
15 region = "eu-west-1"
16}
17data "external" "sneak" {
18 program = [
19 "aws",
20 "sns",
21 "create-topic",
22 "--name",
23 "in-terraform-plan",
24 "--region",
25 "eu-west-1",
26 "--output",
27 "json"
28 ]
29}Granted, this would require the appropriate AWS permissions to be available in your execution environment but:
How many of us use the same permissions for a plan and apply operation?
How many externally-managed Terraform solutions provide the option for separate ones?
#ZeroTrust - our next steps
We knew we needed to be able to separate permissions for a Terraform plan and Terraform apply.
We also knew that:
- If we were on main branch, we could be running a plan or an apply
- On any other branch, we would be running a plan
We considered tying down CI/CD build agents to run specific jobs and permanently granted the required permissions (e.g. an instance profile on an AWS EC2). But we were aware that this could increase both the maintenance overhead of the CI/CD system and also increase the available attack surface. We needed to make sure that build agents could not accidentally or maliciously execute jobs they weren’t supposed to, or inadvertently grant permissions to any other agent with the same shared permanent creds.
For both security and convenience, we were looking for our build agents to be unprivileged, allowing us to use any we liked and to retrieve credentials that were scoped to the specific requirements of the job in hand at the point it began to execute.
Enter OpenID Connect (OIDC)

OIDC is an authentication extension to Open Authorization (OAuth). It provides verifiable claims for the identity of an agent using a system. These claims are defined in a JSON Web Token (JWT) and for CI/CD jobs, they will likely include information such as the source git repository and branch that is executing. For GitHub, an example JWT payload is:
1{
2 "jti": 1234567,
3 "sub": "repo:twinstreamltd/myrepo:ref:refs/heads/main",
4 "aud": "https://github.com/twinstreamltd",
5 "iss": "https://token.actions.githubusercontent.com",
6 "nbf": 1632492967,
7 "exp": 1632493867,
8 "iat": 1632493567
9}This token is signed by the CI/CD system so that jobs can’t be altered after the point of issue. AWS can be configured to trust these tokens and allow them to be exchanged for AWS specific IAM credentials using the AWS Security Token Service (STS).
On the AWS side, we used an IAM Identity provider to trust tokens issued by GitHub and a trust policy on an AWS IAM Role which specifies exactly which tokens can be used for which roles:
1{
2 "Version": "2012-10-17",
3 "Statement": [
4 {
5 "Effect": "Allow",
6 "Principal": {
7 "Federated": "arn:aws:iam::123456123456:oidc-provider/token.actions.githubusercontent.com"
8 },
9 "Action": "sts:AssumeRoleWithWebIdentity",
10 "Condition": {
11 "StringLike": {
12 "token.actions.githubusercontent.com:sub": "repo:twinstreamltd/myrepo:ref:refs/heads/main"
13 },
14 "StringEquals": {
15 "token.actions.githubusercontent.com:aud": "sts.amazonaws.com"
16 }
17 }
18 }
19 ]
20}Notable in the above is the sub claim check in the Condition Statement.
1"StringLike": {
2 token.actions.githubusercontent.com:sub": "repo:twinstreamltd/myrepo:ref:refs/heads/main"
3}The policy asserts that we are on the main branch, and that if we are not, the call to STS should fail. It allows us to create as many roles as needed to give us the granularity required for different branch permissions. Azure has a similar concept using Managed Identities.
Terraform and OIDC in tandem
With the two systems working together:
- When a user modified the Terraform source code, a build job was kicked off in the CI/CD system
- The CI/CD solution issued a JWT, which was exchanged for a set of AWS credentials
- If the build job tried to gain credentials for a role it did not have access to, AWS denied the exchange
- For jobs not running on the main branch, the AWS IAM role for the build job would only allow read-only operations
- Had a user committed malicious code, it would have failed, as the credentials would not have allowed any AWS write access
- Where build jobs were isolated from each other on the CI/CD system, there was no requirement to allocate build agents to individual or privileged operations, reducing both maintenance and risk
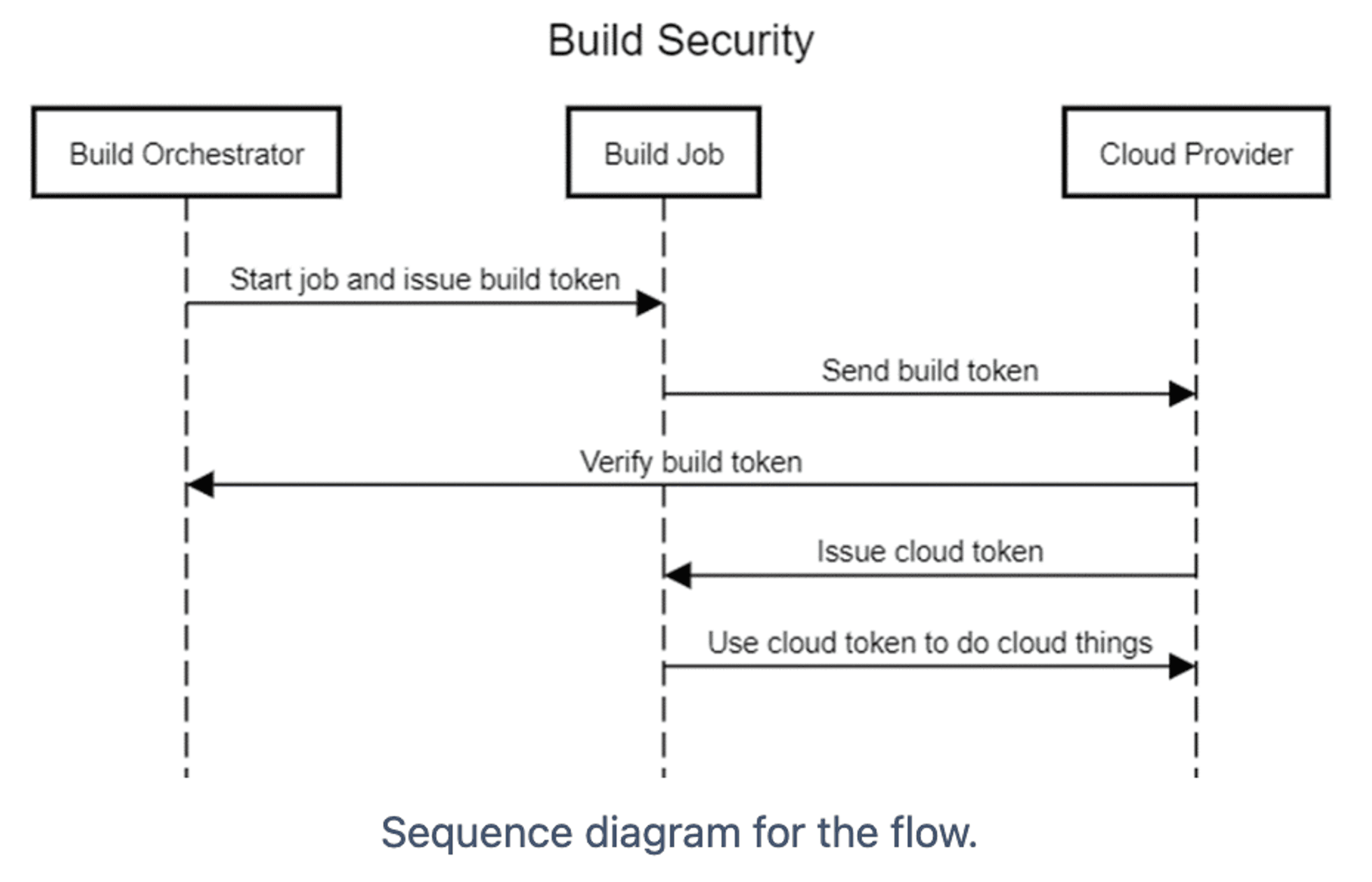
Having implemented the above, we'd successfully ensured that malicious code couldn't abuse our Terraform pipeline to perform write actions before that code had been peer-reviewed and merged into main. We had vetted the integrity of our providers and third party libraries and were moving towards a sustainable solution.
The TwinStream Twist
Whilst the ever-popular GitHub was used in the examples above, our standard CI/CD tool at TwinStream is a self-hosted Jenkins with code repositories in Bitbucket Cloud. For this project, we needed to use both Bitbucket pipelines and AWS CodePipeline to achieve our goals, because:
- AWS' integration with Bitbucket requires granting full access to all repositories. We had repositories which required signed NDAs to access and also did not want to grant new companies direct or indirect access to control the AWS or Azure parts of the project.
- Using exclusively Bitbucket pipelines would have indirectly granted Atlassian access to our entire solution.
Bitbucket pipelines have OIDC capabilities but have different claim formats to GitHub:
1{
2 "sub": "{REPO_UUID}:{STEP_UUID}",
3 "aud": "ari:cloud:bitbucket::workspace/WORKSPACE_UUID",
4 "stepUuid": "{xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx}",
5 "iss": "https://api.bitbucket.org/2.0/workspaces/WORKSPACE/pipelines-config/identity/oidc",
6 "repositoryUuid": "{REPO_UUID}",
7 "branchName": "BRANCH_NAME",
8 "nbf": 1632492967,
9 "exp": 1632493867,
10 "iat": 1632493567
11 "pipelineUuid": "{PIPELINE_UUID}",
12 "workspaceUuid": "{WORKSPACE_UUID}"
13}This proved quite challenging to work with for a number of reasons:
- When we asserted conditions on the token, we wanted to know: the organisation (workspace, in Bitbucket terms); the repository; branch name; who issued the token and the desired audience for the token. In GitHub, this information is all available in the standard sub, iss and aud claims. But in Bitbucket, we also had to check the custom branchName claim. When using AWS STS, there is a limited range of available context keys to allow for conditional checking. These are: aud, azp, amr and sub, which meant we could no longer directly check what branch we were using on the IAM Role Trust policy.
- Bitbucket has an optional ENVIRONMENT_UUID field that can form part of the sub claim. Environments can be restricted to specific branches however, at the time of the project adding branch restrictions to environments was not controlable using infrastructure as code and therefore deemed not suitable.
- The randomised { STEP_UUID } in the sub claim changes at every step of every pipeline run - it requires regex support for the consuming party as it cannot be asserted on with a static value. At the time of the project, Azure did not support this.
- The { and } characters that are included in many claims are not allowed in AWS tags which also meant we couldn’t directly use them for sts:TagSession conditional checks.
All of these issues meant we could not directly use Azure managed identities nor AWS STS to exchange our Bitbucket issued JWTs for cloud credentials.
An Unlikely Hero
Surprisingly, it was AWS Cognito that came to rescue. Not only does Cognito provide another mechanism to exchange OIDC JWTs for AWS credentials, but it can also act as an Identity Provider itself and issue OIDC JWTs. With these capabilities we could solve both issues.
When exchanging an OIDC JWT for AWS credentials, Cognito allows you to create rules which assert conditions on the claims in the token like AWS STS. Unlike STS, Cognito allows any claim to be used, custom or otherwise. With this addition, we could now assert that our branchName was valid.
For Azure access, we were able to change our policy to trust Cognito instead of Bitbucket and use the OIDC JWTs Cognito issues to gain access to Azure resources.
The ultimate solution
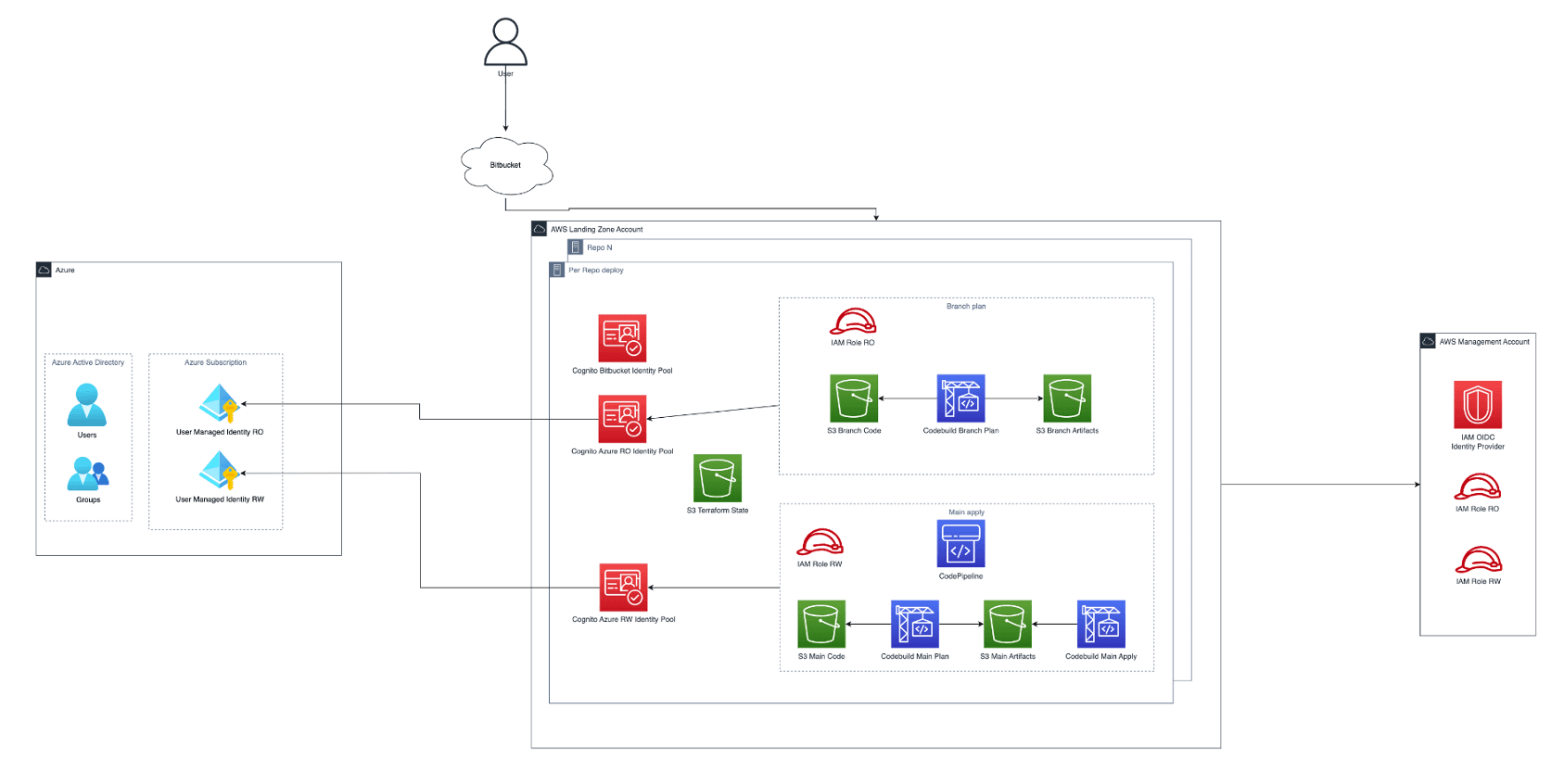
It was quite the journey to get to a solution that was secure, efficient and satisfied all our requirements, with Terraform, OIDC, Bitbucket and AWS Cognito all part of the automation and the interplay between them part of continuous learning of the TwinStream teams.
Written by Huw McNamara, edited by Helen Bradshaw